


How Entity SEO Is Reshaping Modern Organic Search and AI Visibility
[TL;DR]
- Search engines and AI systems understand the web through entities, not keywords
- Entities are distinct, identifiable things: people, places, organizations, concepts
- Google's Knowledge Graph contains billions of these entities and maps how they relate to each other
- These relationships enable search systems to understand meaning and context beyond keyword matching
- Entity recognition now determines visibility across traditional search, AI citations, and answer engines
An Introduction to Entity-Based SEO
To understand why entities matter now, we need to go back to where this all started. Let me pull you into a little historical detour. Back in 2005, a San Francisco company called Metaweb set out to build something different: Freebase, which they described as “an open, shared database of the world’s knowledge.”
The platform allowed users and developers to create, edit and connect structured data about real-world concepts. Metaweb raised tens of millions in venture funding over a few years (including a big round in 2008), but never shipped a commercial product in the traditional sense.
In July 2010, Google acquired Metaweb for an undisclosed sum and gained access to Freebase’s structured graph of millions of “things”.
Fast forward to May 2012, Google launched the Knowledge Graph publicly. Drawing heavily on Freebase (alongside other sources like Wikipedia and the CIA World Factbook), the Knowledge Graph was “a critical first step towards building the next generation of search.”
This gave birth to the popular “things, not strings” philosophy. This was Google’s way of describing a shift from matching words to modeling the real world as a network of identifiable things and their relationships. Picture a network where each point represents a ‘thing’, each line between points represents a relationship, and attached to each point are all the facts Google knows about that ‘thing’
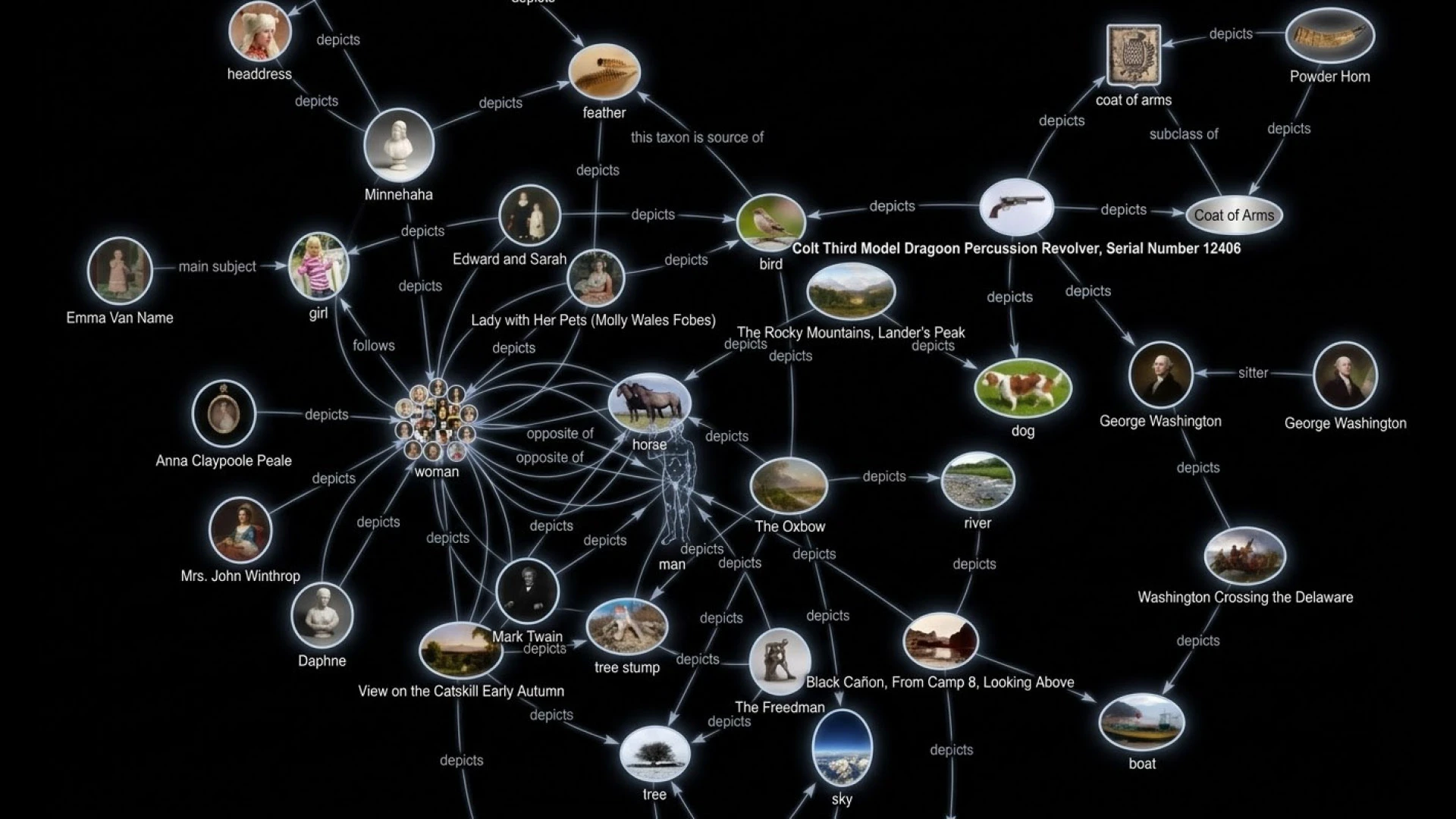
That network describes Google's Knowledge Graph, which is essentially a massive database of ‘things’ (or entities) and how they connect to each other. When it launched in May 2012, the Knowledge Graph contained 570 million entities and 18 billion facts. By 2016, that grew to 70 billion facts. By 2020, it hit 500 billion facts about 5 billion entities.
This is the foundation that sits upstream of everything: traditional SEO, answer engines, generative systems, and AI-powered search experiences. And this is what this article explores in great detail: what entities are, how search and AI systems use them, and why understanding entities now underpins SEO and generative visibility.
What Are Entities in SEO?
Google defines an entity in their 2016 patent as "a thing or concept that is singular, unique, well-defined, and distinguishable." Essentially, it’s a distinct element in a knowledge base, defined by properties that remain consistent over time.
That sounds academic, so let's make it concrete.
People, places, organizations, products, locations, ideas—there are all entities. That looks eerily close to the definition of a noun. So yes, we can think of entities as the nouns of the internet.
Barack Obama is an entity. So is New York City. So is your local coffee shop. So is the iPhone 16. Even concepts like “supply chain management” or “credit risk” count as entities because they’re distinct, well-defined ideas.
Basically, if something could have its own Wikipedia page, it's probably an entity (though not every entity needs a Wikipedia page to exist).
Back to the patent. Google outlined four characteristics that make something an entity:
- Singular (represents one specific thing)
- Unique (distinct from everything else)
- Well-defined (has clear attributes)
- Distinguishable (you can tell it apart from similar things)
You can see these criteria reflected in practice in Google’s Cloud Natural Language API. When given a sentence, it highlights only the entities that meet those conditions, whether they are organizations, locations, products, or dates.
Here’s an example for the sentence: “Apple released the iPhone 15 in California in September 2023, introducing new features for consumers worldwide”
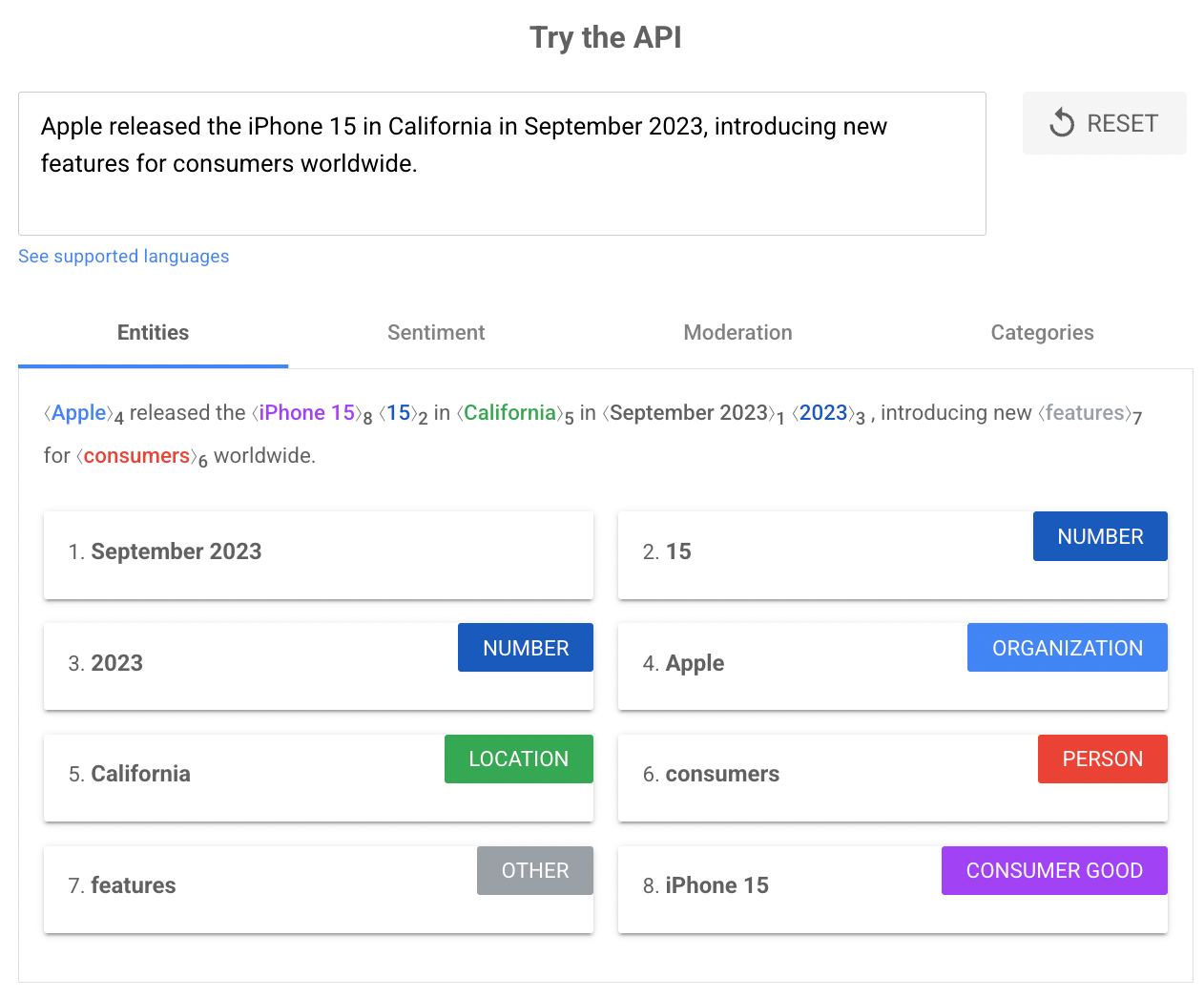
The API categorizes entities into types: PERSON, ORGANIZATION, LOCATION, PRODUCT, EVENT, WORK_OF_ART, CONSUMER_GOOD, DATE, NUMBER, PRICE, PHONE_NUMBER, and OTHER.
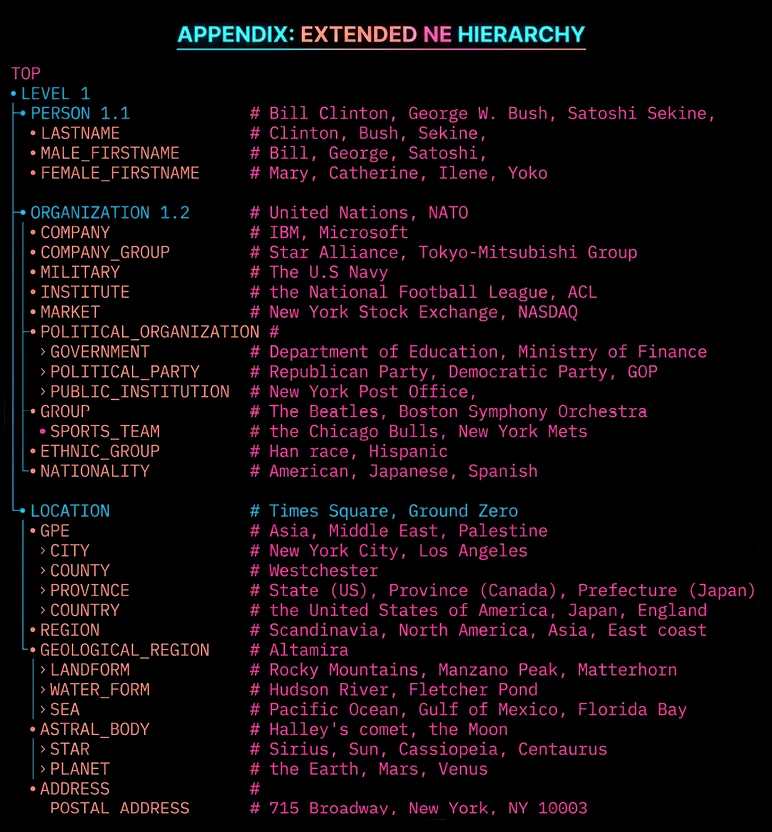
It goes beyond this. In 2002, Satoshi Sekine and his team at NYU published research on Extended Named Entities, proposing a hierarchy of approximately 150 entity types, later expanded to 200 types.
In systems like Wikidata, every entity is assigned a QID, a persistent identifier that acts like a reference number behind the scenes. For example, Barack Obama is Q76. The 1988 Summer Olympics is Q8470.
At least this way, the algorithm can tell entities like Mercury the planet (Q308) from mercury the element (Q925) even though the word is identical.
Google uses a similar approach in its Knowledge Graph through Machine IDs (MIDs), which appear in formats like /m/… and /g/… (for example, /m/02mjmr or /g/11c6w04bhz).
Let me explain better. If you search for “Taylor Swift” on Google, you’d see something like this:
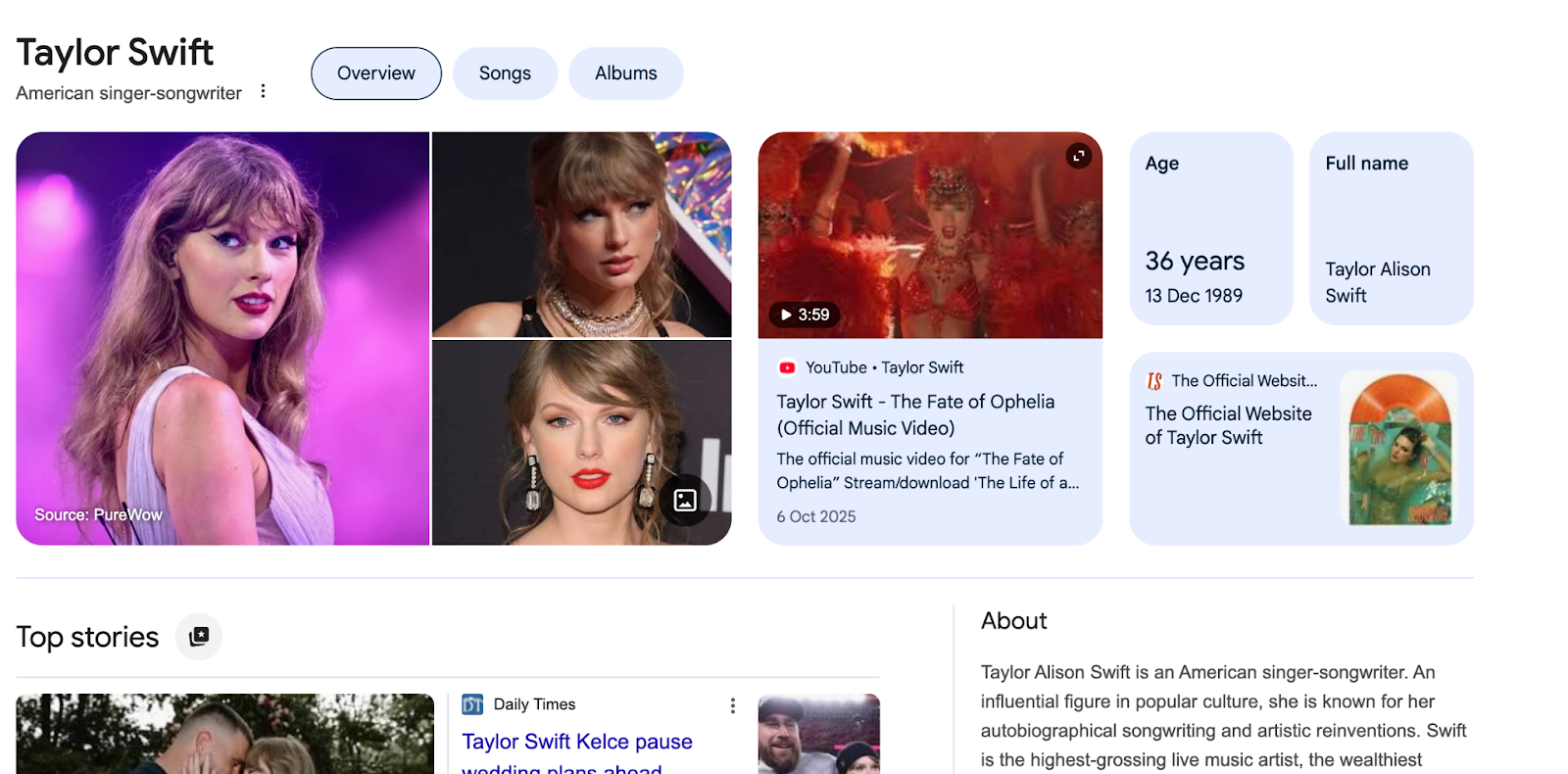
By the way, this is known as a knowledge panel, which is powered by the Knowledge Graph. This shows up when Google recognizes your query matches a known entity. “Taylor Swift” is the main entity. Because she’s recognized as a singer, tabs for her songs and albums are included, alongside other information that makes sense for a public music artist.
If you inspect the page source for this result, you’ll find her Knowledge Graph identifier embedded in the background (/m/0dl567).
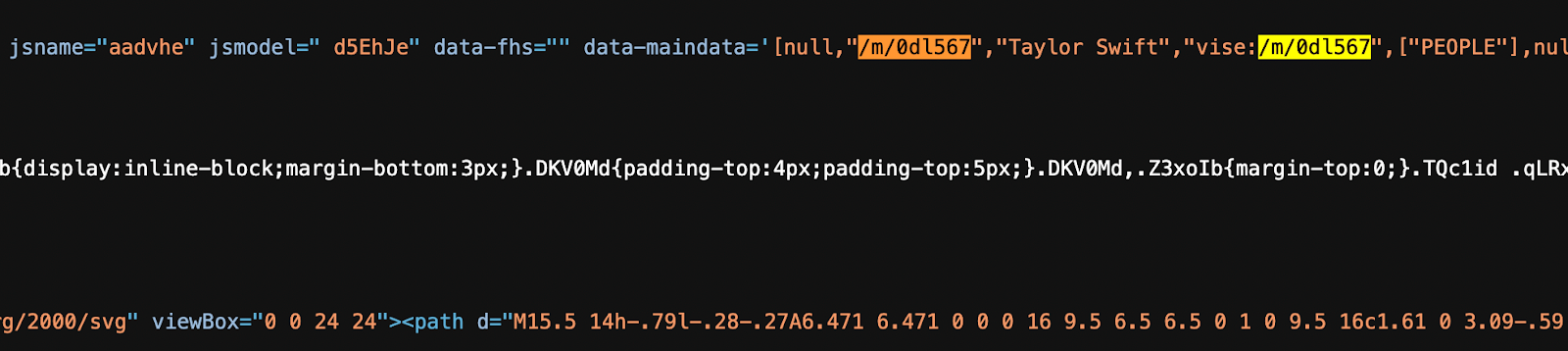
You don’t see this ID as a user, but it’s how Google knows that every mention of “Taylor Swift” across pages, languages, and contexts refers to the same real-world person.
Are Entities, Keywords, and Topics the Same Thing?
At this point, it becomes natural to ask how entities relate to the concepts SEOs already work with every day. Keywords, topics, and entities all describe aspects of meaning, and in practice they often appear in the same workflow, which is why the boundaries between them are easy to blur.
A keyword is just a string of text. A topic is a way of grouping related ideas. An entity is something else entirely. It’s a specific, uniquely identifiable thing that exists regardless of how you describe it.The Mechanics Behind Entity-Based SEO
Natural Language Processing (NLP) bridges that gap by parsing text to extract meaning, identify entities, and understand relationships. This sits at the foundation of information retrieval—finding and returning relevant content from massive document collections.
This process involves recognition, disambiguation, linking, and ranking. These work together to figure out what entities exist in your content and how they connect to what systems already know.
Named Entity Recognition and Disambiguation
Named Entity Recognition (NER) detects and classifies spans of (unstructured) text into predefined categories. When NER processes the sentence "Demis Hassabis founded DeepMind in London before Google acquired it for around $600 million," it identifies four potential entities:
- Demis Hassabis (person)
- DeepMind (organization)
- London (location)
- Google (organization)
But NER on its own is just pattern recognition. It doesn't know which Demis Hassabis you mean (there could be multiple people with that name) or whether "London" refers to London, England or London, Ontario. That's where disambiguation comes in.
Entity Disambiguation solves this by using context to determine which specific entity you mean. In the sentence above, the context tells us:
- Demis Hassabis is the one who founded DeepMind (not someone else with the same name)
- "London" is connected to "DeepMind" and "Google,", so it's probably London, England
- The $600 million acquisition detail confirms we're talking about the DeepMind acquisition that happened in 2014
This kind of resolution has been part of Google’s systems for a long time. A 2007 Google patent on entity disambiguation describes how entity mentions are matched against possible entities in a knowledge base. Each candidate is scored based on how well it fits the surrounding text, and the most likely match is selected.
The algorithm also links entity mentions to entries in knowledge bases. For Google, that's the Knowledge Graph. For Wikipedia-based systems, it's Wikidata or DBpedia.
This linking step enables entity-based understanding. The knowledge base entry contains everything the system knows about that entity: attributes, relationships, facts, and connections to other entities.
So when your content references the same entities and demonstrates understanding of the same relationships, the algorithm recognizes semantic relevance.
Entity Salience and Ranking
Once entities are identified, systems assess entity salience to determine which entities matter most in a document. This helps to determine which entities define the page, and which ones are just supporting context.
Salience is measured on a scale from 0 (barely relevant) to 1 (primary focus). Google uses this to understand which entities represent the core subject matter of your content versus which ones are mentioned in passing.
In 2014, Google researchers Jesse Dunietz and Daniel Gillick published "A New Entity Salience Task with Millions of Training Examples", showing how this can be done at scale by learning which entities tend to represent the “aboutness” of a document rather than treating every mention equally.
That explains how importance is determined within a single page. A 2015 Google patent, Ranking Search Results Based on Entity Metrics, sheds more light on how Google evaluates and compares entities beyond the document level.
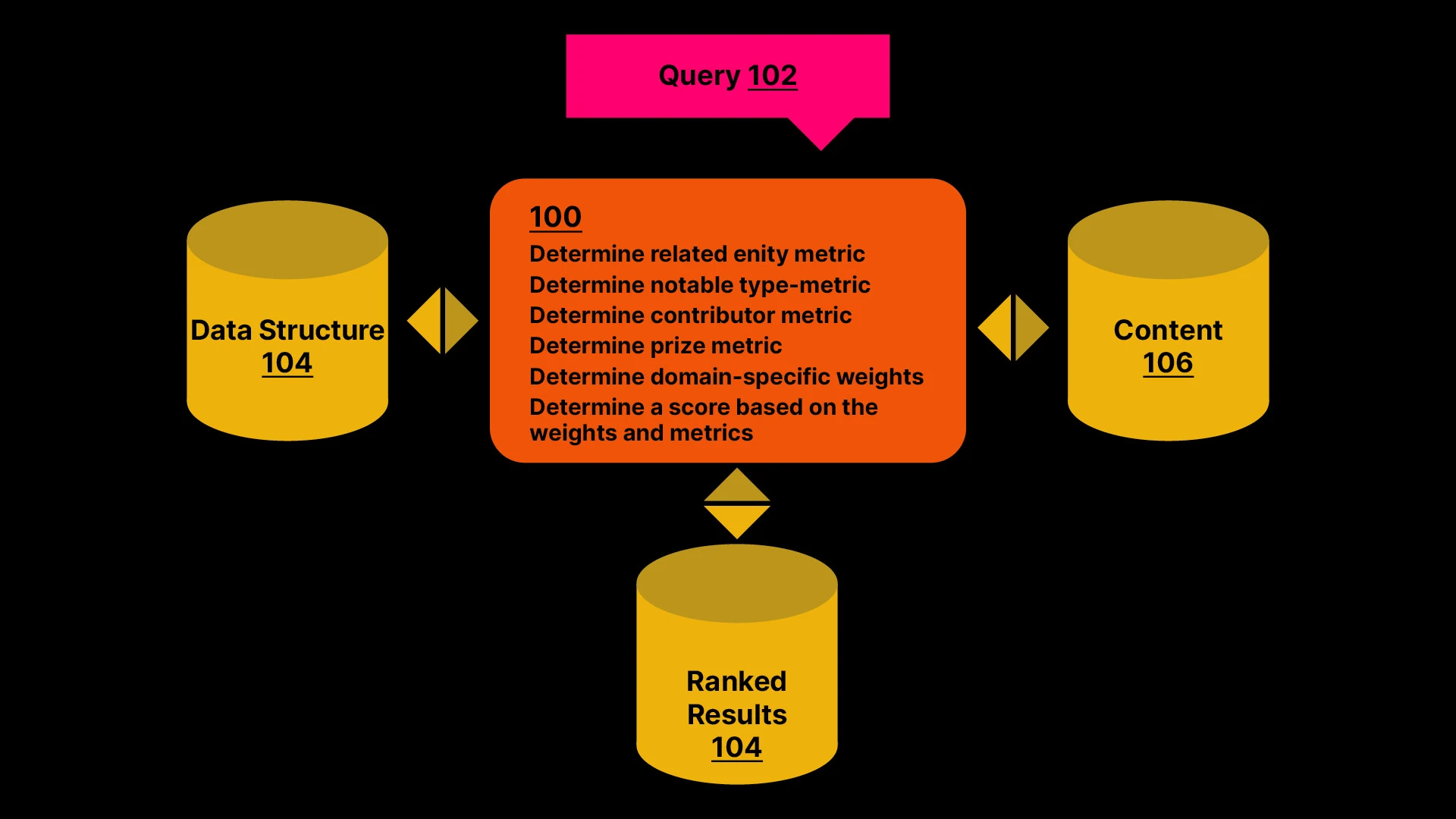
From the image above, we can deduce four metrics to determine how entities rank and relate to each other. Here’s how the patent describes it:
- [0014] “...In some implementations, the system makes use of four particular metrics: a relatedness metric, a notable entity type metric, a contribution metric, and a prize metric”
- [0017] “...In some implementations, the relatedness metric is determined based on the co-occurrence of an entity reference contained in a search query with the entity type of the entity reference on web pages.”
- [0018] “...In some implementations, the value of the notable entity type metric is a global popularity metric divided by a notable entity type rank. The notable entity type rank indicates the position of an entity type in a notable entity type list.”
- [0019] “...In some implementations, the contribution metric is based on critical reviews, fame rankings, and other information.”
- [0020] “...The prize metric is based on an entity's awards and prizes. For example, a movie may have been awarded a variety of awards such as Oscars and Golden Globes, each with a particular value.”
In practical terms, relatedness measures how often an entity appears alongside other relevant entities. Notable entity type reflects importance within a category, where some entities naturally carry more weight than others. Contribution captures impact through reviews, citations, or public recognition. Prize tracks formal recognition such as Nobel Prizes or Oscars.
All of this ties directly into Google’s E-E-A-T framework: Experience, Expertise, Authoritativeness, and Trustworthiness. When Google recognizes your brand as an entity with clear expertise in specific areas, strong relationships, and credible signals, it reinforces authority. Sites and brands with stronger positions in the Knowledge Graph tend to benefit from trust signals that influence rankings.
Vector Representations and Semantic Similarity
Google's Hummingbird update in 2013 marked the pivot from keyword-based matching to semantic search, enabling the system to understand query intent rather than just matching strings. Around the same time, Google introduced Word2Vec, which represented words as vectors in multidimensional space.
BERT in 2019 pushed semantic understanding further with bidirectional context, disambiguating "bank" in "river bank" versus "bank account" based on surrounding words.
These advances rely on representing language as vectors: numerical coordinates in high-dimensional space. This means that words that are similar in some respect have similar values in their embeddings being similar.
The ever famous example: king - man + woman ≈ queen
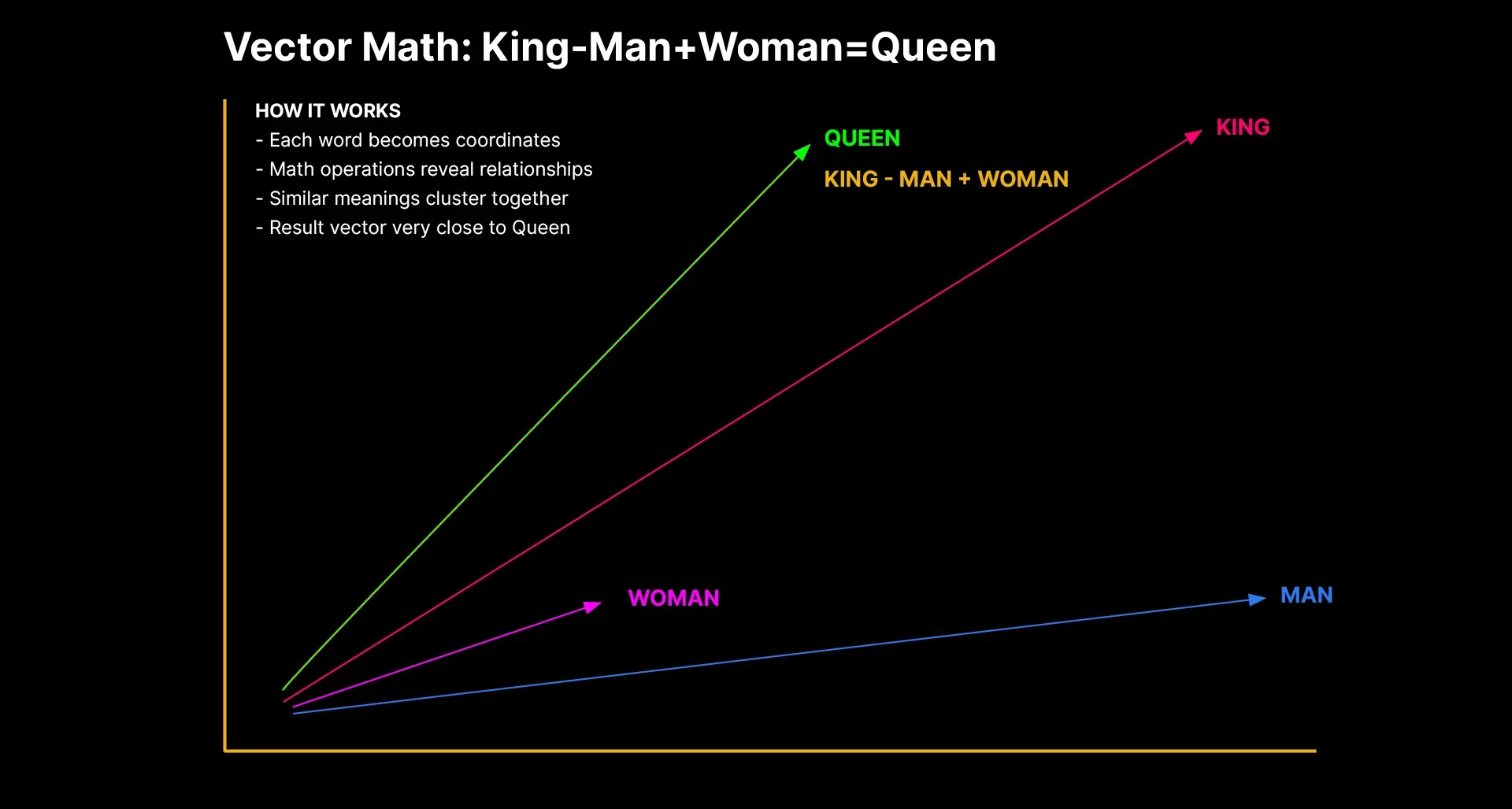
When you subtract the vector for "man" from "king" and add "woman," the result is closest to "queen" in the vector space.
Google maps queries to vectors, identifies entities in that semantic neighborhood, and returns relevant results even when your exact words don't appear on the pages.
You can measure semantic precision by converting both your page content and entity descriptions into vector embeddings.
Cosine similarity, which is a mathematical measure of alignment between vectors, shows how closely your content matches the canonical entity description. Higher similarity scores indicate stronger semantic precision, helping verify that your content accurately represents the entities you claim to discuss.
Why Entities Lay the Groundwork for GEO
The entity structures that search engines recognize also determine which sources AI systems cite.
Let’s break it down. If you were to ask LLMs, say ChatGPT or Perplexity a question, it spits out a synthesized answer in real time with citations pointing to source materials.
The nature of this is very probabilistic but from observation and wide-spread research, citation tends to favour sources that are semantically clear, factually grounded, and explicit about the entities they describe and how those entities relate to each other.
Here’s a 2024 case study: researchers from Princeton and IIT Delhi tested what makes content more likely to be cited by AI. They found that citing authoritative sources, adding expert quotations, and including statistics consistently improved how often content was referenced.
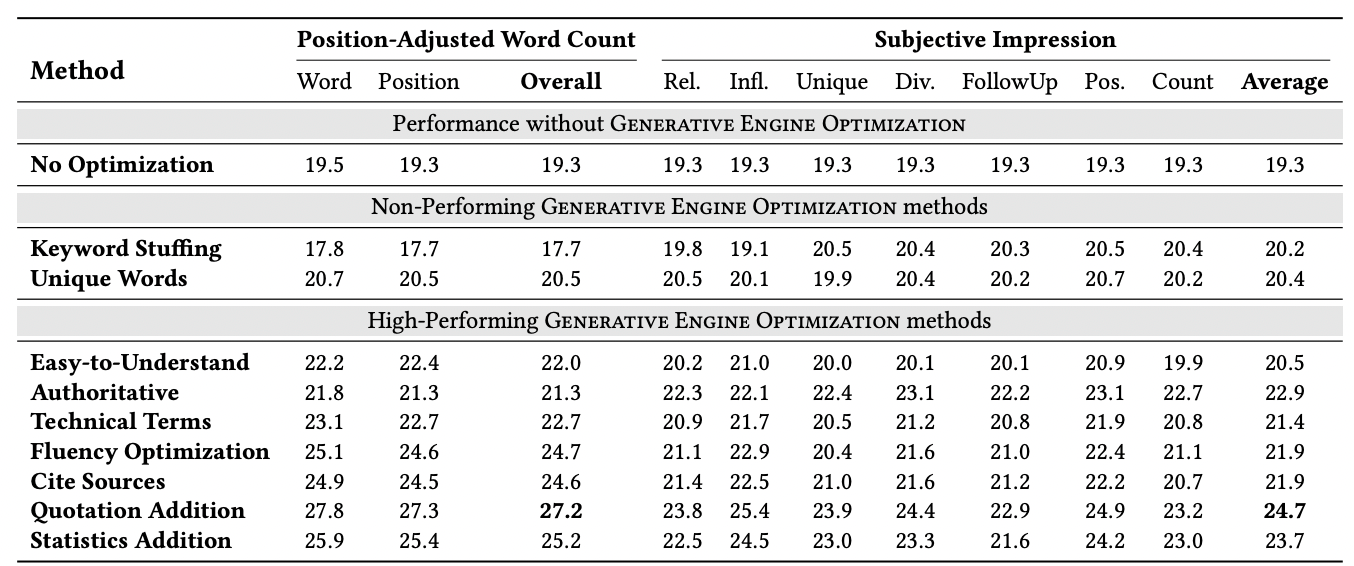
Source: Generative Engine Optimization paper
These techniques share a common thread: they make entities and their relationships explicit.
See it this way. When you write “87% of B2B buyers use AI tools,” you're creating a clear, extractable relationship between entities (B2B buyers, AI tools) with quantifiable data (87%).
This is precisely what LLMs need to confidently extract and cite information. Without clear entity definitions, AI systems face the same problems they encounter with hallucinations.
During training, LLMs learn latent representations that capture entities, their attributes, and their relationships. So when a model encounters content that clearly defines an entity and its properties, that information is easier to extract, retrieve, and reuse.
This lays the bedrock of entity clarity.
According to Profound, ChatGPT cites Wikipedia 7.8% of the time across a dataset of 680 million citations. Why?
Every Wikipedia article is about one primary entity. Take this article as an example.
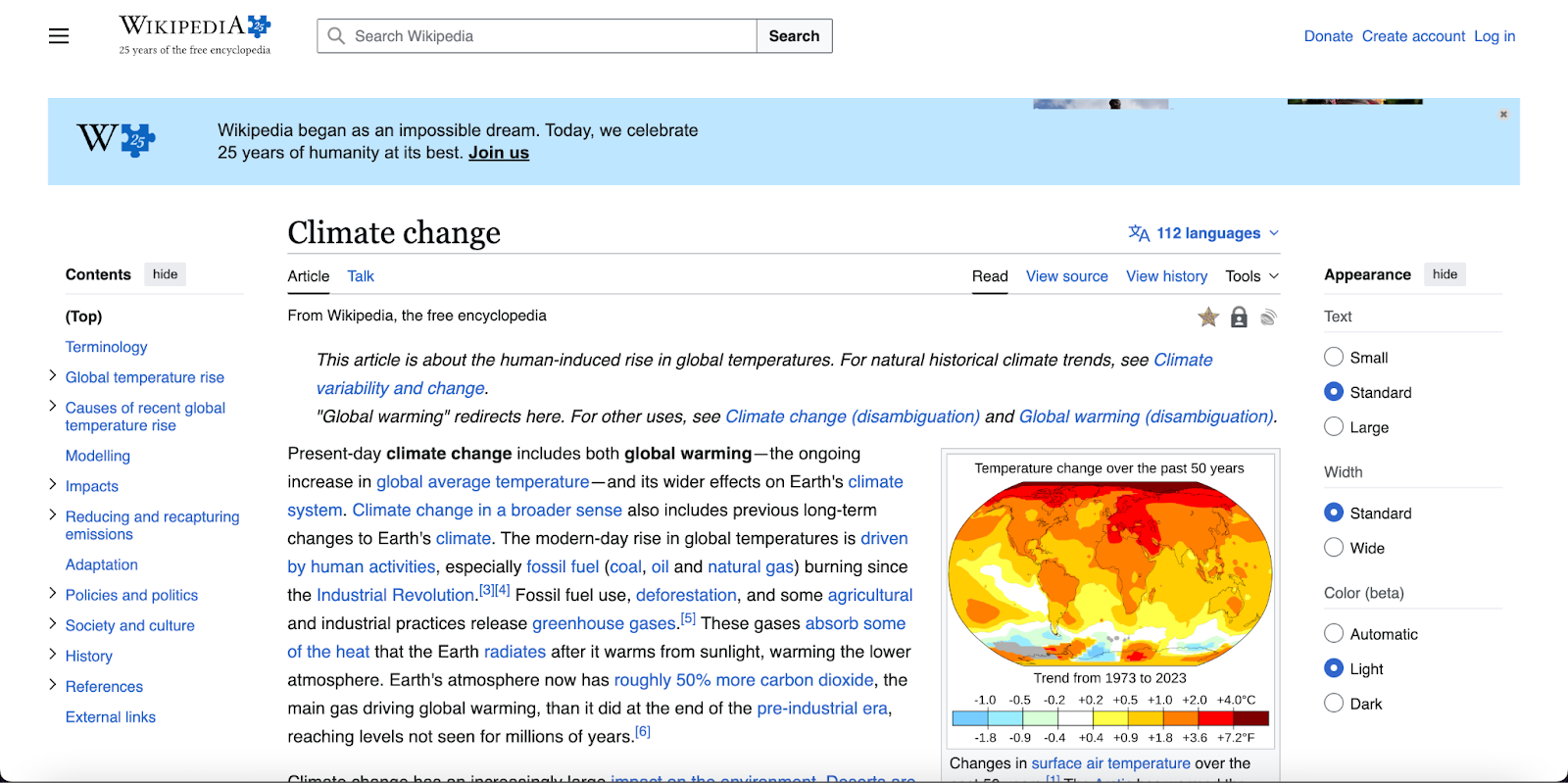
This page establishes what the entity is (climate change), links it to related concepts (global warming, greenhouse gases, fossil fuel use), and distinguishes it from similar terms that are often confused with it.
The structure is replicable:
- One primary entity per page
- Clear definition in the first paragraph
- Explicit categorization (infoboxes, taxonomies)
- Disambiguation from similar entities
- Relationships to related entities through internal links
- Schema markup connecting to stable identifiers
Think of this as a knowledge graph in practice: each Wikipedia page is a node representing a distinct entity, internal links are edges connecting related entities, and the structured data (infoboxes, categories, schema) provides the labels and attributes that define relationships.
When you structure your site this way, with each page representing one canonical entity, connected through meaningful relationships to related entities, you're building a mini knowledge graph that systems can parse and understand.
Wikipedia keeps appearing not because it is always the most detailed or original source, but because it consistently solves the hardest problem first: making entities unambiguous and placing them inside a clear, stable network of meaning.
This principle extends beyond your own site. External entity mentions matter too.
Research from Semrush found that improving brand visibility on platforms such as Reddit increased AI share of voice from 13% to 32%. Why? Because these platforms are rich with entity mentions and relationship discussions.
Without entity recognition, both on your site and across external sources, you're invisible to AI citation systems regardless of content quality.
How to Optimize for Entities in SEO
Use Schema Markup to Declare Entity Types
Schema.org provides vocabulary for declaring entities in machine-readable format. Instead of hoping search engines correctly identify what you're writing about, you tell them explicitly.
According to Google, “Adding structured data can enable search results that are more engaging to users and might encourage them to interact more with your website, which are called rich results.”
Here’s a basic Schema example for a local business entity
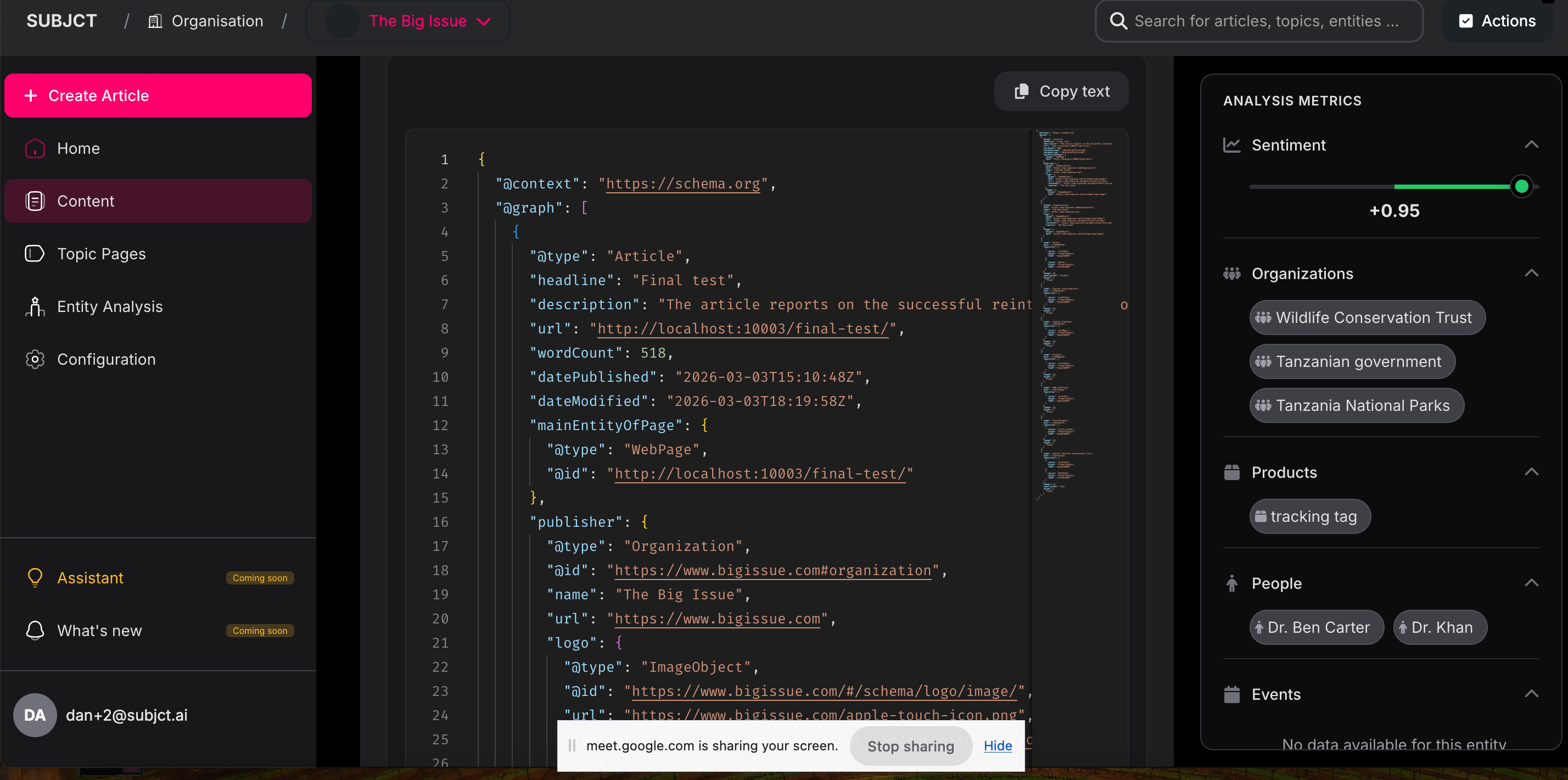
On the Schema Markup Validator, it looks like,
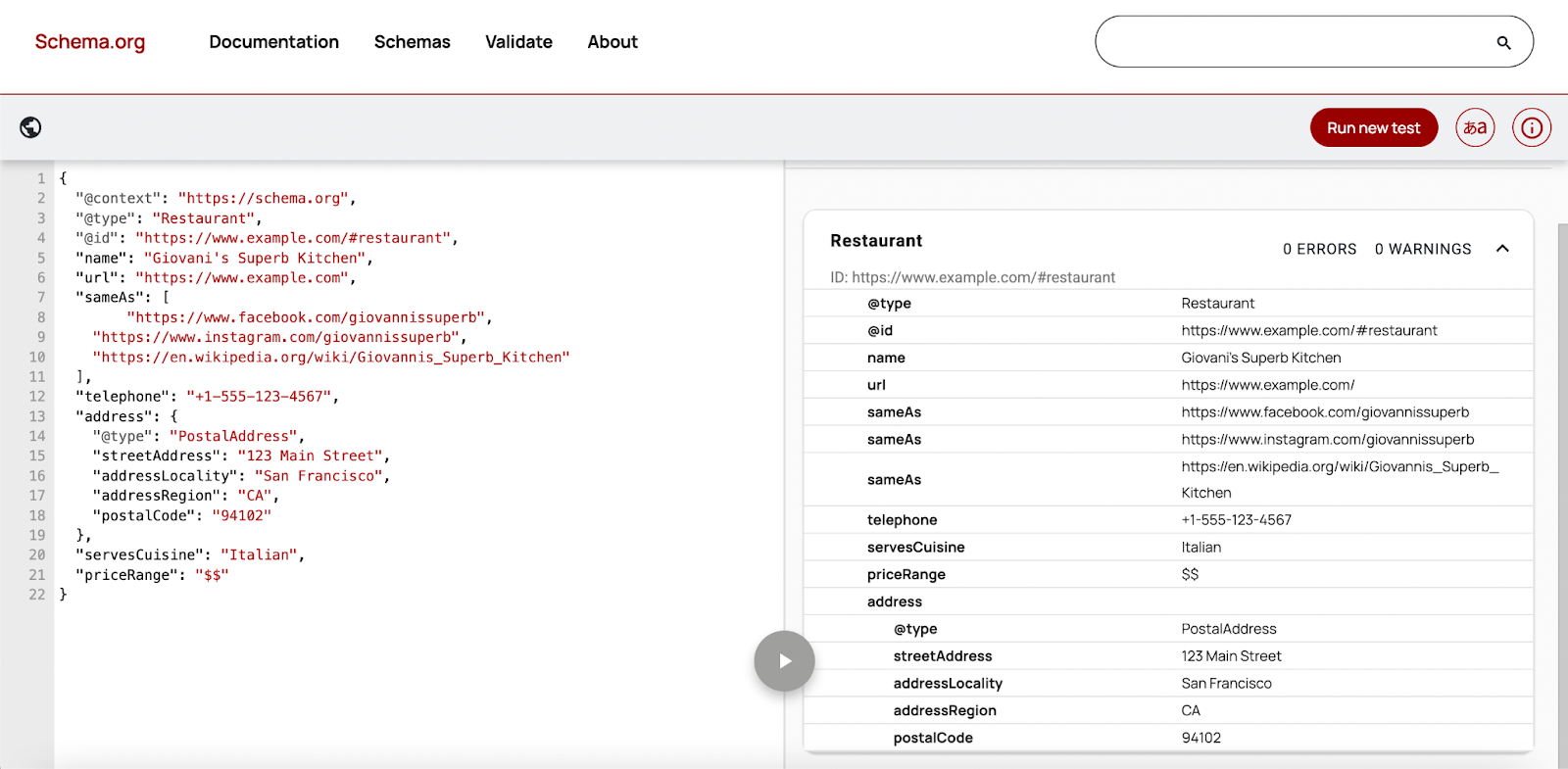
The @id property creates a unique identifier for your entity. The sameAs property connects your entity to authoritative sources, helping Google verify you're a legitimate entity rather than ambiguous text.
When it comes to schema markup, the recommended format is JSON-LD (JavaScript Object Notation for Linked Data), which Google prefers because it keeps structured data separate from HTML, making it easier to implement and maintain.
Analyze Your Content's Entity Coverage
Before you can optimize for entities, you need to understand which entities your content already covers and where the gaps exist.
SUBJCT's entity analysis tool breaks down your content archive by extracting organizations, products, people, events, locations, and other entity types.
For example, when we analyzed a technology publisher's archive of 1,400 articles (1.4 million words), we identified high-level categories first, then extracted entity coverage across organizations.

This level of granularity reveals patterns. Say you're covered "Facebook" 249 times but "Netflix" only 23 times, that's a gap. These disparities show where your content lacks the entity depth needed to establish comprehensive topical authority.
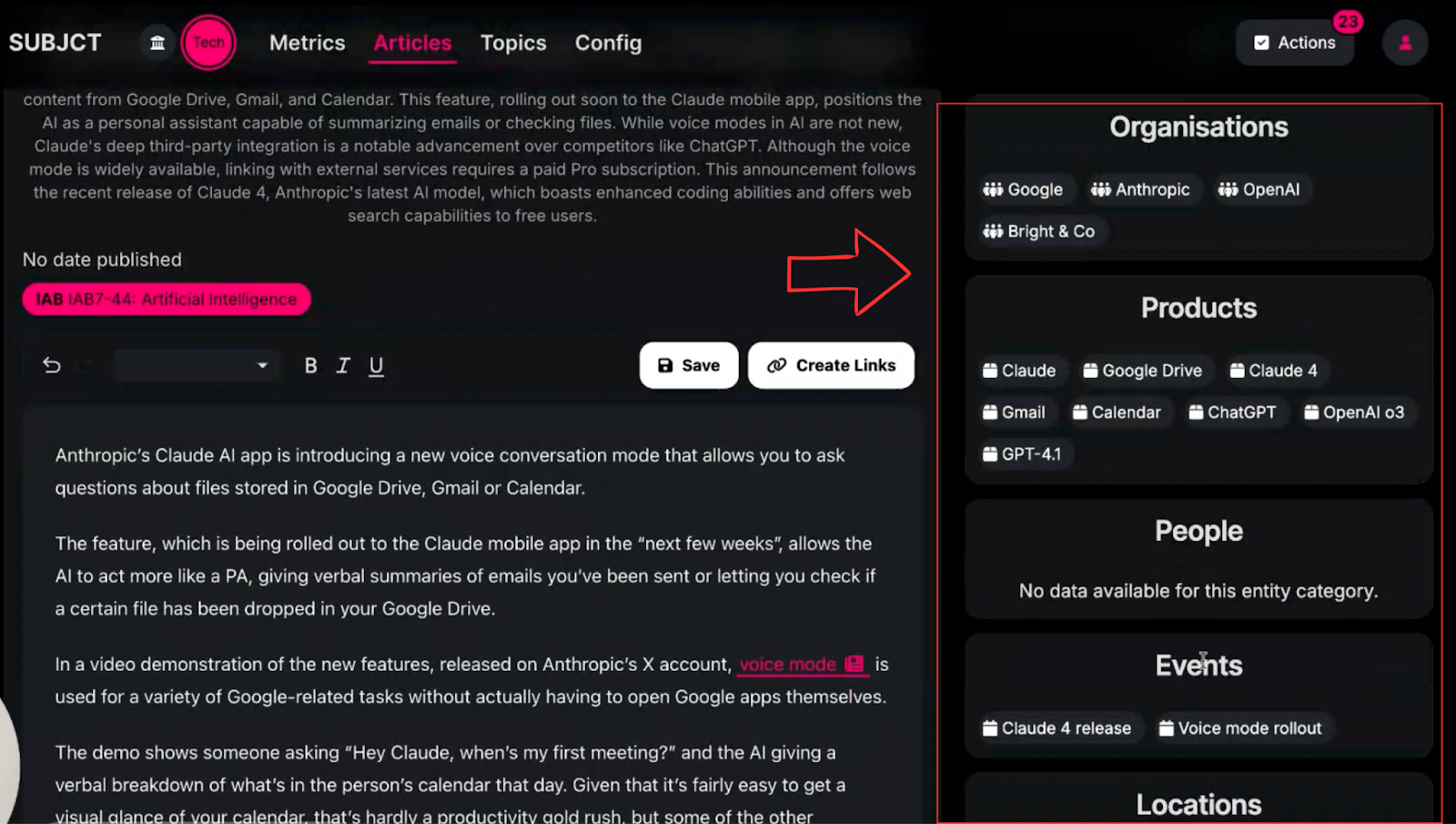
For individual articles, automated entity extraction identifies every organization, product, person, and location mentioned. These entities can then be used to generate automated tags in priority order, ensuring consistent entity recognition across your entire site.
Structure Content Around Relationships
How you structure sentences determines how easily search engines can extract entities and their relationships. There are a few ways to go about that.
Lead with explicit entity definition. See: "Mistral AI is a French AI company founded in 2023 by former DeepMind and Meta researchers building open-source large language models."
The sentence above establishes entity name, type, location, temporal attribute, founder backgrounds, and product focus.
The subject-predicate-object relationship provides a clearer overview.
Example: "GPT-4 implements attention mechanisms"
- Subject: GPT-4 (the entity)
- Predicate: implements (the relationship)
- Object: attention mechanisms (what it relates to)
This creates the triple: (GPT-4, implements, attention mechanisms)
When you write "GPT-4 implements attention mechanisms, a core architectural component of transformer models introduced in the 2017 paper 'Attention Is All You Need' by Vaswani et al.," you're creating multiple triples:
- (GPT-4, implements, attention mechanisms)
- (attention mechanisms, component of, transformer models)
- (paper, published in, 2017)
- (paper, authored by, Vaswani et al.)
Each semantic triple makes an entity relationship explicit. The more explicit these relationships, the easier entity extraction becomes. Garbage in, garbage out.
Maintain consistent naming too. Choose one primary name and stick to it. If you introduce "Retrieval-Augmented Generation (RAG)" then use "RAG" consistently afterward. Don't alternate between "RAG," "retrieval augmentation," "augmented retrieval," or "the RAG approach." Pick one label. Inconsistent naming confuses entity resolution for both traditional search and AI systems trying to cite you.
Build Topic Clusters Around Core Entities
Your site architecture should reflect entity relationships. When you create content around a core entity, supporting content should link back to a central hub page that comprehensively covers that entity.
The mechanics are straightforward:
- Identify your core entities (the topics you want to be known for)
- Create comprehensive hub pages for each core entity
- Build supporting content that covers related sub-entities
- Link supporting content back to the hub using entity names as anchor text
- Ensure the hub page links out to all supporting content
When done well, topic clusters transform isolated articles into interconnected knowledge that demonstrates topical authority and entity expertise. Topic clusters work because they mirror how knowledge graphs are structured: a central entity node with relationships branching out to related entities.
Build External Entity Validation
Consistent external mentions matter. When your brand appears in industry publications, gets cited in research, shows up on conference speaker lists, or gets discussed in podcasts, Google sees patterns that verify your entity status.
For local businesses, start with NAP consistency. Name, Address, and Phone details should match exactly across Google Business Profile, Yelp, industry directories, and local citations.
Verified profiles on major platforms help too. LinkedIn, Crunchbase, Twitter, official social accounts with verification badges. These platforms run their own entity systems, and verification signals legitimacy across multiple sources.
Each mention from a credible source builds your entity profile. The key is consistency. Use the same brand name, link to the same official site, and maintain the same positioning.
How SUBJCT Automates Entity Optimization
Throughout this article, we've covered entity recognition, disambiguation, salience, relationship structures, and knowledge graph alignment.
While the mechanics are clear, for many, the challenge is execution at scale.
For sites with hundreds or thousands of pages, manually identifying entities, building topic clusters, maintaining consistent naming, structuring relationship triples, and implementing schema across every article doesn't scale.
SUBJCT entity analysis platform helps to automate this:
- Entity extraction: Identifies organizations, people, products, places, and events across your content archive
- Entity analysis: Shows which entities you've covered, where gaps exist, and which entities need dedicated pages
- Automated tagging: Applies entity tags in priority order based on what the content actually discusses
- Schema implementation: Connects your entities to broader knowledge graphs through structured data
- Internal linking: Builds link structures that mirror entity relationships, creating the kind of semantic connections systems recognize
- Content recommendations: Surfaces related content based on shared entities and relationships
For large publishers particularly, this analysis combined with automated tagging and linking transforms fragmented archives into structured knowledge systems that both search engines and AI can confidently parse and cite.
Get in touch to see how this works for your content operation.
Frequently Asked Questions
What are examples of entities?
Entities can be people (Satya Nadella, Fei-Fei Li), organisations (Microsoft, DeepMind, Stripe), products (GPT-4, Claude), locations (Lagos, Shenzhen, Berlin), concepts, or really anything that can be uniquely identified with a name, attributes, and relationships to other entities. The key characteristic is that an entity has an entry in a knowledge base (Google's Knowledge Graph, Wikidata, Wikipedia) with a unique ID, known attributes, and defined relationships to other entities.
What is the difference between keywords and entities?
Keywords are what people type into search boxes. Entities are the concepts algorithms extract from those keywords. A keyword like "best CRM software" is a string of text with no fixed meaning beyond the query itself. "Salesforce," on the other hand, is an entity with a Knowledge Graph entry, a QID in Wikidata, known attributes (founder, headquarters, product category), and defined relationships to other entities like Marc Benioff and cloud computing. Keywords describe how people search. Entities describe what search systems understand.
How do I know if Google recognises my brand as an entity?
Search for your brand name in quotes on Google. If a Knowledge Panel appears on the right side with information about your company, Google has you in the Knowledge Graph. Other signals include Google autocompleting your brand name in search, your brand appearing in "People also search for" sections under related entities, and branded searches showing a company card. You can also check whether your Google Business Profile is verified and whether your brand appears in Google's entity-related features like Featured Snippets with attribution.
Does entity SEO replace keyword research?
No. Entity optimisation builds on keyword research, it does not replace it. You still need to understand what queries people use and what search volume exists. But entity SEO shifts the focus from "how many times should I mention this keyword" to "have I made it clear which entities I'm discussing and how they relate to user intent." The two disciplines work in tandem: keyword research tells you what people are asking, and entity optimisation ensures your content answers those questions in a way that algorithms can structurally parse.
Should every page on my site be about one entity?
Not necessarily, but each page should have a clear primary entity. Wikipedia's one-entity-per-page model works because it eliminates ambiguity, but your content strategy might require discussing multiple related entities on a single page. The key is hierarchy: make it clear which entity is primary (through title, H1, schema markup, early mentions) and how other entities relate to it. If a secondary entity starts demanding significant depth on a page, that could be a signal it deserves its own dedicated piece.
How does entity SEO affect local search rankings?
Local search has always relied on entity recognition, even before most SEOs started using that language. When Google matches a "coffee shop near me" query to a specific business, it is resolving an entity: matching a user's intent to a known thing with a name, address, category, and set of attributes stored in its systems. NAP consistency (Name, Address, Phone) across Google Business Profile, directories, and citations is really just entity disambiguation for local businesses. The more consistently your business appears as the same entity across multiple sources, the more confidently Google can surface you for relevant local queries. Reviews, photos, and category selections all function as entity attributes that strengthen that recognition.
What is the relationship between entity SEO and E-E-A-T?
Google's E-E-A-T framework (Experience, Expertise, Authoritativeness, Trustworthiness) is essentially a qualitative overlay on entity recognition. When Google assesses whether a page demonstrates expertise on a topic, it is evaluating whether the entities discussed are handled with depth and accuracy, and whether the author or brand behind the content has its own entity signals that support credibility. A medical article written by someone with a recognised Knowledge Graph entry as a physician carries different entity-level trust signals than the same article written anonymously. Building your brand and your authors as recognised entities with clear expertise signals, publication history, and consistent external mentions is how E-E-A-T moves from an abstract guideline to something structurally measurable.
Can entity SEO help content rank in AI answer engines like ChatGPT and Perplexity?
This is where entity clarity becomes a direct competitive advantage. AI answer engines work by retrieving and synthesising information from sources they can parse with confidence. Content that clearly defines its primary entity, states factual relationships explicitly, and structures information in extractable patterns (definitions, comparisons, statistics tied to named entities) is more likely to be cited. The Princeton and IIT Delhi research referenced earlier in this article found that content with authoritative citations, expert quotations, and concrete statistics consistently improved AI citation rates. All of those techniques share a structural foundation: they make entities and their relationships unambiguous. If an LLM cannot confidently identify which entity your page is about and what claims you are making about that entity, it has little reason to cite you over a source where those signals are clearer.
How do I measure whether my entity SEO efforts are working?
Traditional keyword rankings remain one signal, but entity optimisation opens up additional measurement dimensions. Start by checking whether your brand triggers a Knowledge Panel on Google, which indicates Knowledge Graph recognition. Monitor whether your content appears in Featured Snippets, People Also Ask boxes, and AI-generated overviews, all of which rely on entity-level understanding. Tools like Google's Natural Language API can show you which entities Google extracts from your pages and how salient they are, giving you a before-and-after comparison as you optimise. For AI visibility specifically, track whether your brand or content gets cited in LLM responses using tools like Algorythmic's LLM visibility scanner. The compounding signal to watch for is this: as your entity clarity improves, your content should begin appearing across more retrieval surfaces (traditional search, AI citations, answer engines) rather than ranking for isolated keywords alone.
Do I need a Wikipedia page to be recognised as an entity?
Having a Wikipedia page is one of the strongest signals for entity recognition, but it is not the only path. Google's Knowledge Graph pulls from multiple sources, including Wikidata, Google Business Profile, authoritative news mentions, Crunchbase, and structured data on your own site. Plenty of local businesses, niche software products, and emerging brands are recognised as entities without Wikipedia entries. What matters is that your entity information is consistent, structured, and verifiable across multiple sources. Schema markup on your site, a verified Google Business Profile, consistent mentions in industry publications, and a Wikidata entry with a QID can collectively build the same kind of disambiguation that a Wikipedia page provides. That said, if your brand could plausibly meet Wikipedia's notability guidelines, pursuing a page remains one of the highest-leverage entity SEO investments available.
Ready to Optimize Your Content?
Get in touch to find out more about our suite of content optimization tools built for AI search.
Join Beta
Related Articles
Content Optimization Platform for AI search.