


Semantic SEO: What It Is and How It Works
[TL;DR]
- Semantic SEO is the practice of optimising content for meaning and context.
- Search engines have shifted from matching words to understanding entities and relationships.
- Modern search systems rely on mechanisms like the EAV model, vector embeddings, and query fan-out to interpret and retrieve meaning at scale.
What Is Semantic SEO?
Semantic SEO is the practice of optimizing content for meaning, context, and the relationships between real-world concepts (entities).
If you're familiar with entity SEO, semantic SEO is the broader practice that entity optimisation sits within. The word "semantic" comes from the Greek sēmantikos ("significant" or "meaningful"), derived from sēmainein ("signify" or "indicate by a sign").

In linguistics, semantics is the branch of study concerned with how language conveys meaning: not just what words say, but what they imply, what context they create, and how they relate to each other. In SEO, the same principle applies. It means creating content that clearly explains a topic and naturally connects it to related ideas, so search engines can understand how everything fits together rather than just matching individual words.
An Example Of Semantic SEO
Let’s look at how Nike appears in search.
Nike is a globally recognised athletic footwear and apparel brand with a brand value exceeding $30 billion. It operates within a clear competitive set that includes Adidas and Puma, and is strongly associated with concepts like running, performance footwear, and elite athletes.
Because of this, search engines do not treat “Nike” as just a keyword. They understand it as an entity connected to a wider network of meaning. When searching for something like “best shoes for a half marathon,” Google draws on that existing understanding.
When I ran the query in AI Mode (Google's AI-powered search experience that synthesises results rather than listing links), one of the top recommendations was the Nike ZoomX Alphafly 3.
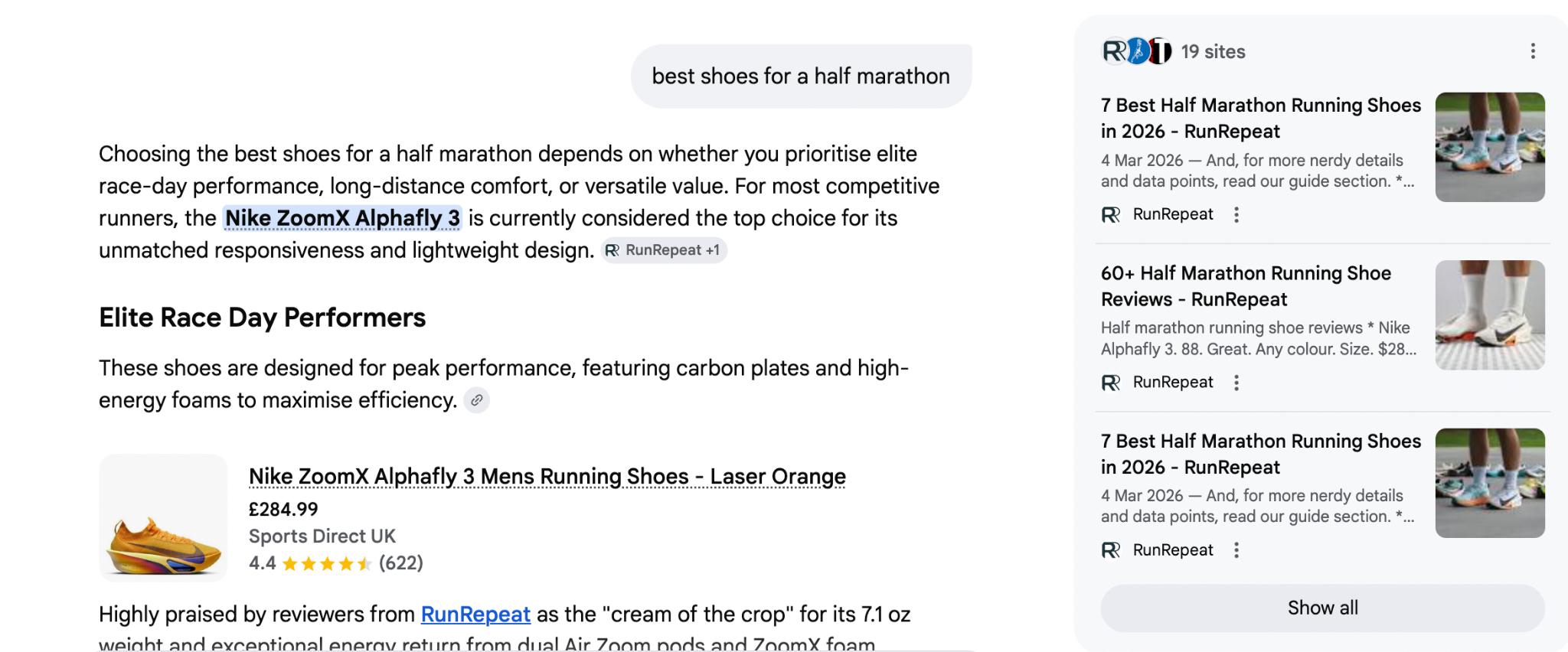
This is not because the page repeats the keyword the most, but because the product sits naturally within a network of relevant entities such as running performance, race-day footwear, elite athletes, and trusted brand authority. This is how modern search works. Google retrieves entities it understands to be relevant and surfaces results that fit coherently into that network.
Why Semantic SEO Matters
The old playbook was simple: put the right phrase in the right locations, title tag, H1, first paragraph, body copy, meta description, and search engines would understand what your page was about.
The underlying questions were "Does this page contain the right keywords?" and "How many times does this keyword appear?" Under Semantic SEO, those questions changed to:
- What concept is this page actually about?
- What real-world things does it reference?
- How do those things connect to each other?
- Does the content genuinely address what someone searching for this topic wants to know, or is it just assembling the right phrases?
Google's ability to interpret meaning, infer intent, and evaluate topical depth has made shallow, keyword-driven content progressively less competitive. If your content doesn't demonstrate a genuine understanding of the subject it covers, it is increasingly unlikely to rank, regardless of how well it’s technically optimised, or how entity-rich it is.
How Search Became Semantic: The Technological Advances Behind It
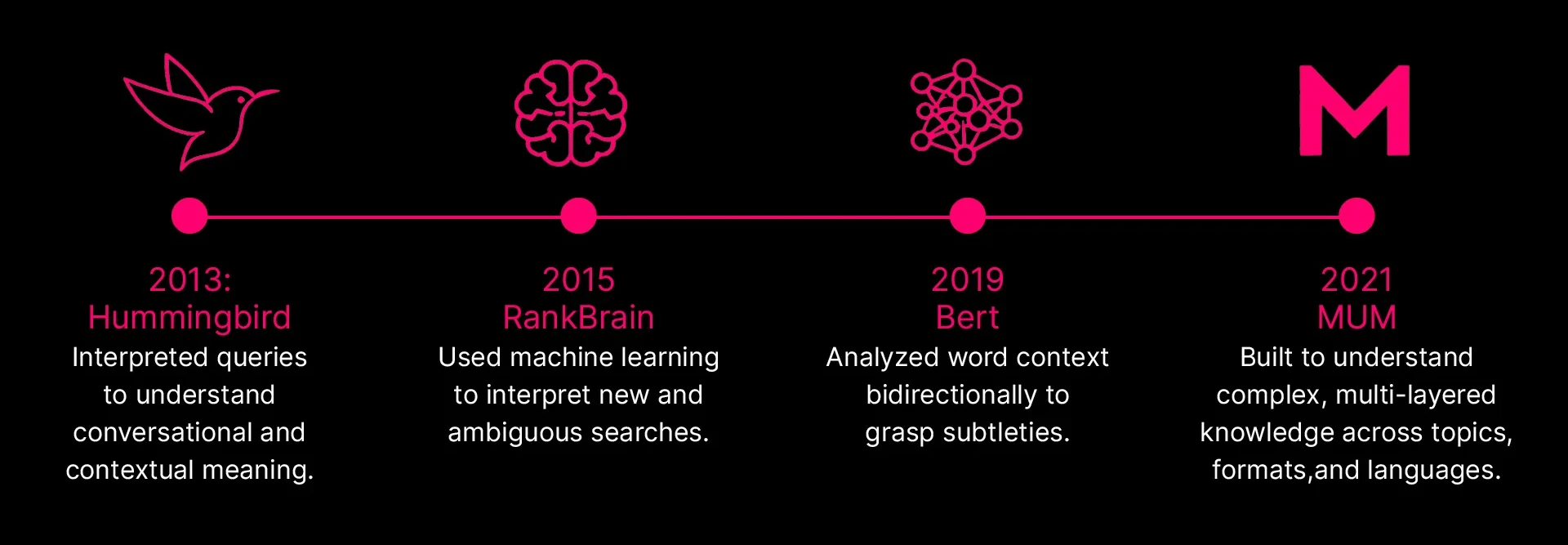
Hummingbird (2013)
Released in 2013, Hummingbird was a full rewrite of Google's core algorithm, with a core ambition to move from matching words to interpreting meaning. Google was contending with a growing volume of long, conversational queries, where people were asking full questions. Hummingbird gave Google the ability to identify which words in a query actually carried semantic weight and which were essentially filler.
RankBrain (2015)
RankBrain followed in 2015, introducing machine learning into search ranking for the first time. Where Hummingbird operated on the structure of language, RankBrain operated on the patterns of behavior. It approached unfamiliar queries by identifying the entities a query referred to and drawing on patterns from similar queries to infer intent.
BERT (2019)
BERT gave Google bidirectional language understanding. Before BERT, the word "bank" in a sentence could be ambiguous. BERT could read the full sentence and determine from the surrounding context whether it meant a financial institution or a riverbank. Applied across billions of queries and billions of pages, this made semantic understanding at scale possible.
MUM (2021)
MUM represented a broader architectural shift. Where the preceding updates each addressed a specific gap in query understanding, MUM was built for a different category of problem entirely: complex, multi-layered questions that require synthesising information across multiple topics, formats, and languages simultaneously.
Taken together, this progression from Hummingbird through MUM traces a deliberate movement in how Google processes information, away from the surface of language and toward the structure of meaning underneath it.
The Anatomy of Semantic Search
Underneath these updates, several core technical mechanisms contribute to how semantic search works.
The Entity-Attribute-Value (EAV) Model
An entity is any real-world thing that can be uniquely identified: people, places, organisations, products, events, concepts. Entities are the foundation of semantic SEO because they are how search engines navigate and interpret your content.
When Google processes a page, it extracts these entities and connects them to its underlying Knowledge Graph, using those connections to understand what the content is actually about. For example, "Python" is an entity. But it is actually three very different entities depending on context: the programming language, the snake, or the Monty Python comedy group.

Google figures out which one you mean through Named Entity Recognition (NER), a process that reads the surrounding context of every mention and resolves ambiguity before any ranking decision is made.
However, entities do not exist in isolation. The relationships between them are what give content semantic depth, and making those relationships explicit is one of the most underrated aspects of semantic optimisation.The system search engines use to store and use entity information is called the Entity-Attribute-Value model, or EAV.
The core idea is that every piece of factual information about a real-world thing can be expressed as a three-part statement:
- the entity (the thing)
- an attribute (a property it has)
- the value of that attribute (the specific answer).
These three-part statements are called semantic triples.
Take Apple Inc. as an example. That single entity generates a structured set of triples:
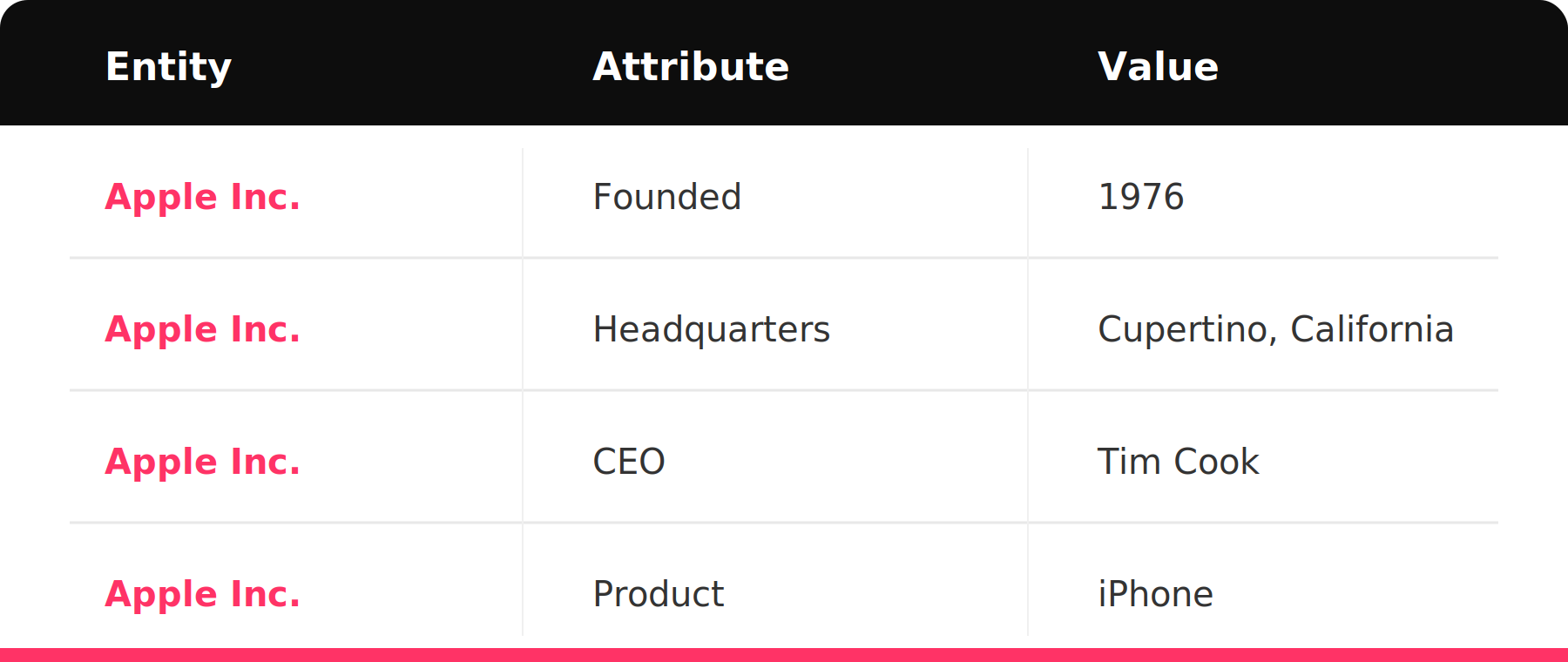
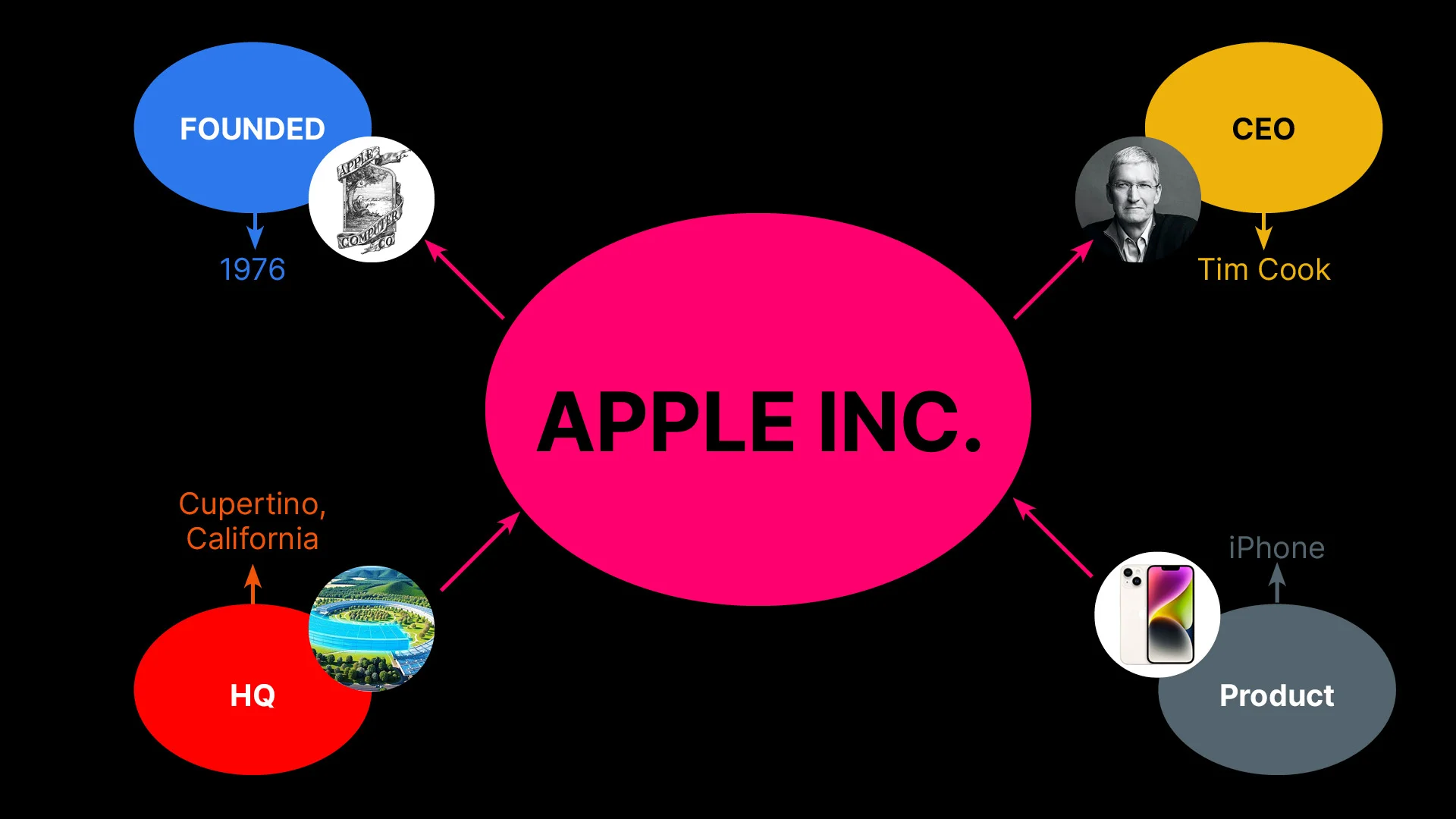
This matters because the density and clarity of the semantic triples that can be extracted from your content are a meaningful signal of its quality. The difference between strong and weak semantic signals comes down to specificity.
Content that makes explicit claims about entities, their attributes, and how they relate to each other gives search engines something concrete to work with. Content that drops entity names without saying anything meaningful about them gives search engines almost nothing.
Embeddings and Semantic Closeness
When Google indexes your content, it does not store the words as raw text for retrieval. It converts your content into vector embeddings: numerical representations that encode the semantic meaning of your text as coordinates in a high-dimensional mathematical space.
Think of it like a map, but with thousands of dimensions. Every word, phrase, and document gets a location on this map.
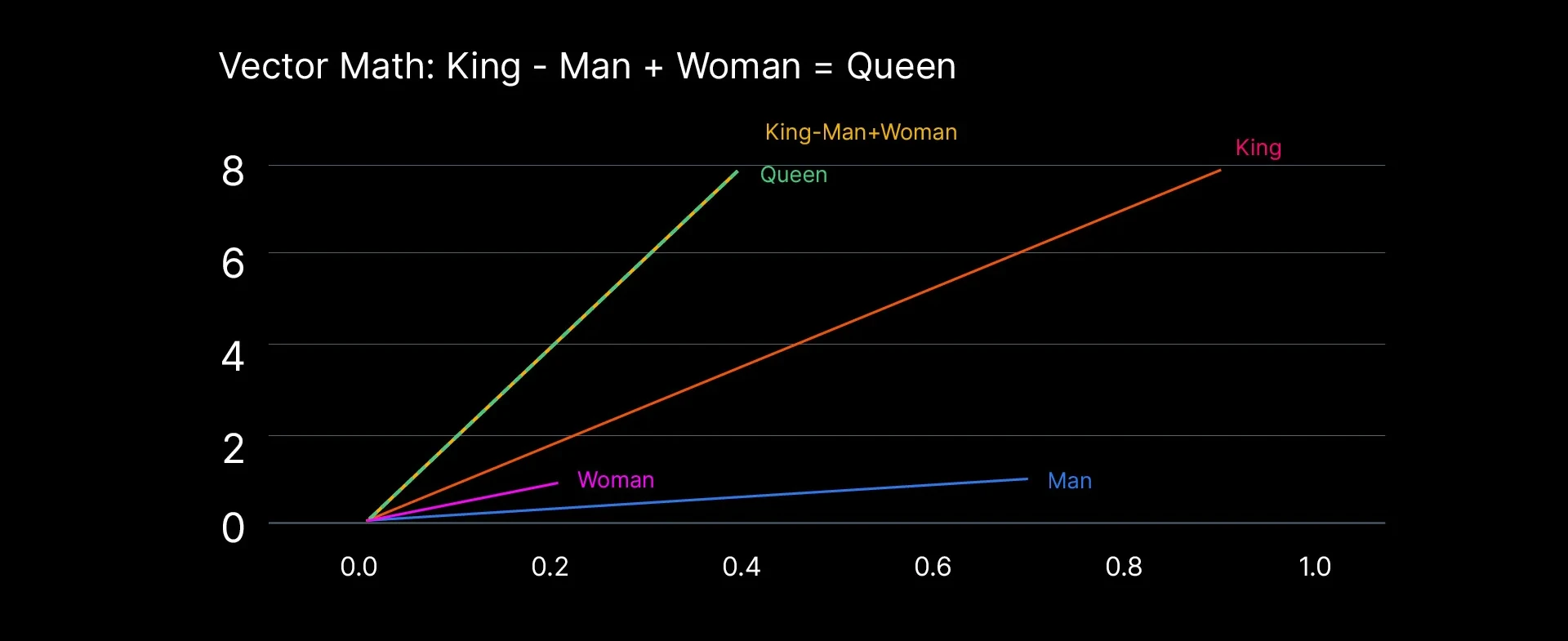
The crucial property is that meaning corresponds to proximity. In other words, concepts that are semantically similar end up close together, while concepts that are unrelated end up far apart. Here’s a well-known illustration: if you take the vector for "king," subtract the vector for "man," and add the vector for "woman," the result lands closest to "queen" in the vector space.
When you submit a query, Google converts it into an embedding and measures how closely your query embedding aligns with the embeddings of documents in its index. The closer the match in vector space, the more semantically relevant the content, regardless of whether your exact words appear on the page.
Topic Clusters and Entity Relationships
One single well-written article cannot build topical authority on its own. Authority is earned through systematic coverage of a subject across multiple pieces of content, each reinforcing the same entity cluster from a different angle.
This is where topic clusters come in.
A pillar page establishes the core entity and its primary relationships, covering the concept comprehensively. Cluster articles go deeper on specific sub-entities and related concepts, each linking back to the pillar using the entity name as anchor text.
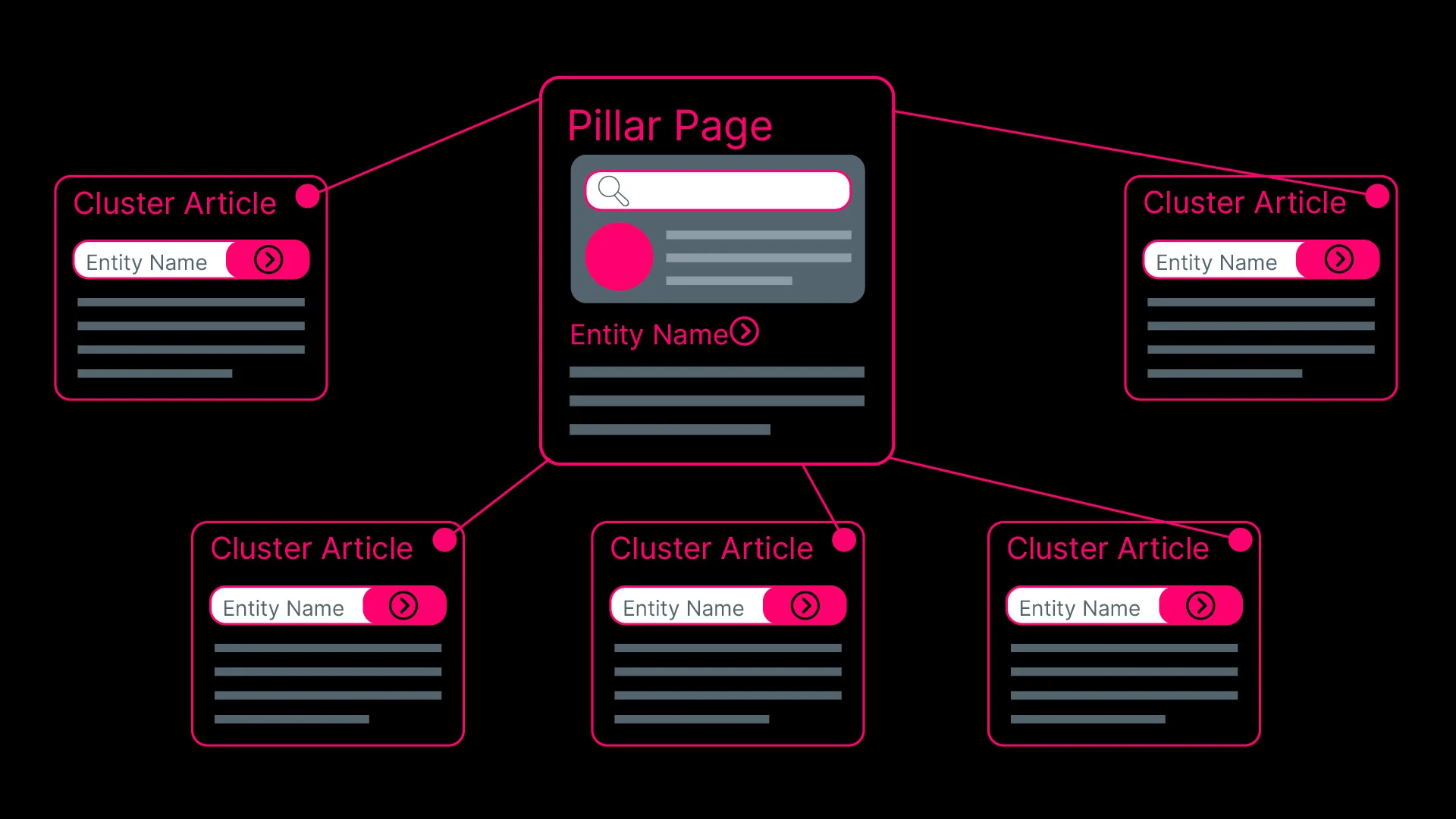
The internal link is not just navigational. It tells search systems that these two pages share an entity relationship, that the cluster concept is a branch of the pillar concept. Consider how Forbes Advisor structures its coverage of VPN services.
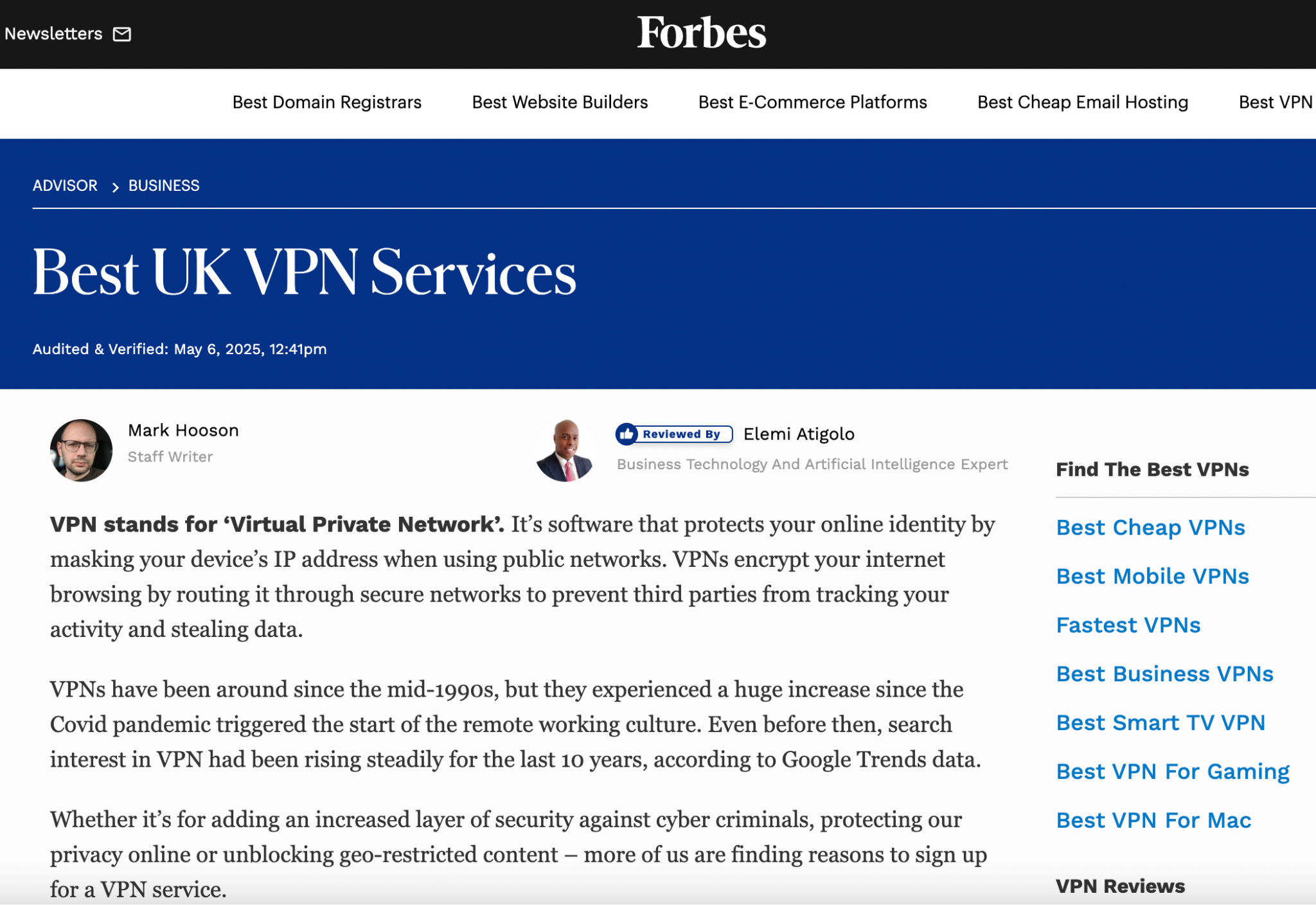
Their pillar page for the best UK VPN services is supported by a surrounding cluster:
- Best cheap VPNs
- Best mobile VPNs
- Fastest VPNs
- Best VPNs for gaming
- Best VPNs for Mac, etc.
Every piece links back to the pillar using entity names as anchor text. Every link reinforces the same cluster. The reason this works at a semantic level is that each cluster article reinforces the same entity associations from a different angle.
Topic clusters work because they mirror how knowledge graphs are structured: a central entity node with relationships branching out to related entities.
Lexical vs. Semantic vs. Hybrid Search
Not all search systems work the same way, and the differences matter for how you structure content.
- Lexical search is the oldest model. It matches the exact words in a query against the exact words in a document. If you search for "content marketing strategy," a lexical system returns pages that contain those specific words. It is fast and predictable, but brittle.
- Semantic search operates on meaning rather than words. Instead of matching strings, it converts queries and documents into vector embeddings and measures conceptual proximity. A search for "heart attack" surfaces pages about "cardiac event" because the concepts occupy the same neighbourhood in vector space, regardless of whether the words overlap.
- Hybrid search combines both. It runs a lexical pass for precision and a semantic pass for recall, then merges the results. Most modern search systems, including Google, operate as hybrid systems. Exact matches still carry weight, but conceptual relevance determines whether content surfaces for queries it was never explicitly written for.
How Semantic SEO Connects to GEO and AI Visibility
The mechanics all described above, entity recognition, vector embeddings, and relationship mapping, are not unique to traditional search. They are the same infrastructure that AI systems use to retrieve and cite sources. This is where semantic SEO and generative engine optimisation (GEO) converge.
When someone submits a question to ChatGPT, Perplexity, or Google AI Mode, the system does not run one search and return a list. Instead, it breaks the query into multiple sub-queries, executes them in parallel, retrieves relevant passages from across the web, and synthesises everything into a single response.
This phenomenon is called query fan-out.
At Google I/O 2025, Elizabeth Reid, Google's Head of Search, explained it directly: “Under the hood, AI Mode uses our query fan-out technique, breaking down your question into subtopics and issuing a multitude of queries simultaneously on your behalf.”
What this really represents is semantic query expansion at scale, powered by the same vector embedding systems outlined earlier.
Each sub-query is matched against content based on semantic similarity. Pages that cover a topic deeply and from multiple angles are more likely to align with multiple sub-queries, increasing their chances of being retrieved and used in the final response.
This is where semantic SEO directly impacts AI visibility. In traditional search, semantic authority helps a page rank. In AI-driven search, it determines whether a brand is cited at all.
Platforms like Google AI Overviews now reach more than 1.5 billion users monthly across over 100 countries. Systems such as ChatGPT process billions of prompts daily, while Perplexity, Gemini, and Microsoft Copilot each surface and prioritize sources differently.
The scale and behaviour of fan-out also varies across platforms, and it is becoming increasingly personalised, shaped by a user's search history, location, and context, meaning the same question can trigger different sub-queries for different people. But despite differences in interface, they all rely on the same core signals: structured content, topical depth, clear entity relationships, and authority built across an interconnected body of work rather than isolated pages.
How to Build a Semantic SEO Strategy
What follows is a prioritised sequence for building a semantic SEO strategy from the ground up.
Start With Entity Clarity
Before anything else, your organisation needs to be a clear, consistent, recognisable entity in the systems that matter. That means:
- an About page that explicitly describes who you are, what you do, and how you relate to the key concepts in your industry.
- Consistent name, address, and description across every platform where you have a presence.
If your founders or key subject matter experts are credible enough to have Wikidata entries or recognised profiles, those connections strengthen your entity authority considerably.
Map Your Topic Territory
A topic map is the blueprint for the content architecture. It identifies core subjects the audience needs to understand, the subtopics surrounding each one, and the questions people ask at every level.
Here is how to build one:
- Identify the core topic area. What is the central subject the brand should own? For HubSpot, that is inbound marketing. For Salesforce, it is an enterprise CRM. Everything else branches from that anchor
- Map the major subtopics. For a brand focused on content marketing, those might be editorial strategy, SEO writing, content distribution, analytics, and repurposing. Each becomes a cluster page
- Map the questions within each subtopic. What does someone who knows nothing about this subject need to understand? What does someone with intermediate knowledge want to go deeper on? These questions become the H2s and H3Ss within cluster pages
- Audit existing content. Which of these topics already have coverage? Which are gaps? Which existing pages are isolated from each other and need to be connected?
The topic map turns a content calendar from a list of random ideas into a deliberate architecture with compounding returns.
Build Pillar Pages That Earn Their Role
A pillar page has one job: to be the most reliable, comprehensive overview of a broad topic on the site, linking out to dedicated cluster pages for depth. A well-built pillar page typically ranges from 2,500 to 4,000 words. It does not try to be the definitive treatment of every subtopic. Instead, it tries to be the clearest, most authoritative overview of the topic as a whole, with natural pathways into deeper exploration.
Structure matters as much as coverage. A well-built pillar page should include:
- Clear H1 that signals the core topic
- Descriptive H2s for each major section
- H3s for subsections where needed
A TL;DR or short summary near the top gives time-pressed readers immediate orientation without forcing them to scroll. Also, an anchor-linked table of contents improves navigation and gives crawlers a cleaner semantic map of the page.
Where relevant, use HTML tables to present comparative information clearly, and include an FAQ section using proper heading tags. Both formats are highly extractable by AI systems and increase the chances of being surfaced and cited across both traditional and AI-driven search.
Implement Schema Markup Systematically
Schema implementation is most effective when treated as a systematic content layer, not a task applied sporadically to a few pages.
Some schema types:
- Organisation (homepage and About page): name, url, logo, foundingDate, description, sameAs links to LinkedIn, Wikipedia, Wikidata, and major social profiles
- Person (author and leadership pages): name, job title, affiliation, sameAs links to professional profiles. This connects the people behind content to recognised entities
- Article (all editorial content): headline, author, datePublished, dateModified, and the about property, which explicitly declares the topic entity the article addresses
- FAQPage (any Q&A content): Each question and answer pair becomes structured data AI systems can extract directly
Here is an example of a SoftwareApplication schema for SUBJCT:

Validate every implementation using Google's Rich Results Test before publishing.
Build Internal Links as Part of Every Publishing Workflow
Internal linking should not be an afterthought or a quarterly project. When a new cluster page goes live:
- Add a link from the pillar page to the new cluster page with descriptive anchor text
- Add a return link from the cluster page back to the pillar
- Identify two or three existing cluster pages covering adjacent topics and add links between them
- Check whether older content covers related ground and could link to the new page naturally
Linking to a pillar page on “best headphones” using "click here" tells Google almost nothing. Linking to it using the actual word "best headphones" tells Google that the page you are linking from is connected to the entity represented by that pillar.
For teams managing large content libraries, doing this manually across hundreds of articles is not realistic. SUBJCT's automated internal linking tool handles this at scale, using vector embeddings to identify semantically related content and automatically generating descriptive anchor text links.
On a quarterly basis, audit for orphan pages (no inbound internal links), under-linked pillar pages, and generic anchor text on high-traffic pages. This best practice ensures compounding advantages over time.'
Write For Depth And Coverage
Each piece of content in your cluster should cover its subtopic comprehensively, include the entities and concepts that naturally belong in any thorough treatment of that subject, and answer the questions a genuinely curious reader would have.
The test is not whether you mentioned the keyword enough times. The test is whether someone who knew nothing about the topic would come away with a thorough understanding of it.
Run a Semantic Gap Analysis
A semantic gap analysis identifies the concepts that belong in your entity cluster but are currently absent from your content.
This is different from a traditional keyword gap analysis. A keyword gap looks for terms your competitors rank for that you do not. A semantic gap analysis looks for concepts: sub-entities and related ideas that any comprehensive treatment of your subject would include, that your content has not addressed.
Here is the manual approach: List the top five pages ranking for your target topic. For each one, extract every major concept covered (sections, sub-topics, entities discussed). Compare those lists to your own content. The concepts appearing consistently across competitor pages but missing from yours are your semantic gaps.
If that sounds like too much work, you can automate the whole process using SUBJCT.
How SUBJCT Automates Semantic Optimisation
Running this process across a handful of articles is manageable. Running it across 500 or 5,000 is a different problem entirely.
Manual entity mapping, gap analysis, consistent internal linking, and schema implementation do not scale. The effort multiplies with every new piece of content, and most publishers cannot maintain the consistency semantic optimisation demands when doing it by hand.
SUBJCT's entity analysis tool is built for exactly this. It scans your full content archive and extracts entity coverage across organisations, people, products, locations, and events, showing what is covered in depth, what has been touched briefly, and what is missing.
Automated internal linking builds contextual link structures based on semantic entity relationships, and automated article tagging applies entity tags in priority order based on what each piece actually discusses.
The result is a content library that behaves like a coherent knowledge system, where every piece reinforces the same entity clusters and where both search engines and AI systems can navigate the relationships between them reliably. Get in touch to see how this works for your content operation.
Frequently asked questions
What is the difference between traditional SEO and semantic SEO?
Traditional SEO focused on placing keywords in specific locations to signal relevance. Semantic SEO focuses on making the concepts, entities, and relationships within your content clear and well-structured. Keywords remain relevant as entry points into topics, but the primary signal is now whether content demonstrates genuine understanding of a subject, not whether it repeats a phrase the right number of times.
Does ChatGPT use semantic search?
Yes, in a meaningful and technically specific way. Large language models like ChatGPT are trained on enormous text corpora, and that training process builds internal vector representations of language where semantically similar concepts end up close together in the model's internal space. When ChatGPT generates an answer, it draws on those representations to surface conceptually relevant information, not just exact phrase matches.
Do semantic tags help with SEO?
Semantic HTML tags like article, section, header, nav, main, and aside help search engines understand the structural role of different parts of your page. They are not a strong ranking signal on their own, but they contribute to crawlability and page structure comprehension. Using them correctly is part of good technical SEO practice, even if they do not directly move rankings.
What is entity recall and why does it matter for AI search?
Entity recall refers to how completely an AI system can retrieve information about a specific entity from its training or retrieval index. When entity recall is strong, the system can accurately interpret queries, connect related topics, and produce richer, more reliable answers. When it is weak, the system may miss important details, or provide incomplete or fragmented responses, which reduces both accuracy and trust.
What is the Entity-Attribute-Value model in SEO?
The Entity-Attribute-Value model, or EAV, is how search engines structure factual information about real-world things. Every piece of knowledge is stored as a three-part statement called a semantic triple: the entity (the thing itself), an attribute (a property it has), and the value (the specific answer). For example, Apple Inc. (entity) has a CEO (attribute) who is Tim Cook (value). The density and clarity of the semantic triples that can be extracted from your content signal its quality to search systems.
What are vector embeddings and how do they relate to SEO?
Vector embeddings are numerical representations that encode the semantic meaning of text as coordinates in a high-dimensional mathematical space. When Google indexes content, it converts text into these embeddings rather than storing raw words. Concepts that are semantically similar end up close together in this space, which means content can surface for queries even when the exact words do not match, as long as the meaning aligns.
What is query fan-out in AI search?
Query fan-out is the process AI search systems use to break a complex question into multiple sub-queries, execute them simultaneously, retrieve relevant passages from across the web, and synthesise everything into a single response. At Google I/O 2025, Elizabeth Reid confirmed that AI Mode uses this technique, issuing a multitude of queries on the user's behalf. Content that covers a topic deeply and from multiple angles is more likely to align with multiple sub-queries, increasing its chances of being retrieved and cited.
How do topic clusters support semantic SEO?
Topic clusters mirror the way knowledge graphs are structured. A pillar page establishes the core entity and its primary relationships, while cluster articles go deeper on specific sub-entities and related concepts. Each cluster page links back to the pillar using the entity name as anchor text, which tells search systems that the two pages share an entity relationship. This structure builds topical authority across an interconnected body of work rather than relying on isolated pages.
What is the difference between lexical search and semantic search?
Lexical search matches the exact words in a query against the exact words in a document. It is fast and predictable but brittle, because it misses conceptual relationships. Semantic search converts queries and documents into vector embeddings and measures conceptual proximity, so a search for "heart attack" can surface pages about "cardiac event" even though the words are different. Most modern search systems, including Google, use hybrid search that combines both approaches.
How does semantic SEO affect AI visibility and citations?
In traditional search, semantic authority helps a page rank. In AI-driven search, it determines whether a brand is cited at all. Platforms like Google AI Overviews reach more than 1.5 billion users monthly across over 100 countries, and systems like ChatGPT process billions of prompts daily. All of these rely on the same core signals: structured content, topical depth, clear entity relationships, and authority built across interconnected content rather than isolated pages.
What is Named Entity Recognition and why does it matter?
Named Entity Recognition, or NER, is the process search engines use to identify entities in content and resolve ambiguity. For example, "Python" could refer to the programming language, the snake, or the Monty Python comedy group. NER reads the surrounding context of every mention and determines which entity is being referenced before any ranking decision is made. Making entities unambiguous in your content helps search systems classify and connect your pages accurately.
How do you run a semantic gap analysis?
A semantic gap analysis identifies concepts that belong in your entity cluster but are currently missing from your content. Unlike a traditional keyword gap analysis, which looks for terms competitors rank for, a semantic gap analysis looks for sub-entities and related ideas that any comprehensive treatment of your subject would include. The manual approach involves listing the top five ranking pages for your target topic, extracting every major concept each one covers, and comparing those lists to your own content. The concepts appearing consistently across competitor pages but missing from yours are your semantic gaps.
Ready to Optimize Your Content?
Get in touch to find out more about our suite of content optimization tools built for AI search.
Join Beta
Related Articles



Content Optimization Platform for AI search.